
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- DB
- 생성자 주입
- Kafka
- EC2
- 스프링의 정석
- CentOS
- 스파르타코딩클럽
- 쇼트유알엘
- visualvm
- Spring Security
- 항해99
- @jsonproperty
- 프로그래머스
- 데이터베이스
- 시큐리티
- WEB SOCKET
- Spring
- emqx
- JavaScript
- 개인프로젝트
- 카프카
- MYSQL
- java
- AWS
- JWT
- docker
- 남궁성과 끝까지 간다
- 웹개발
- 패스트캠퍼스
- 스웨거
- Today
- Total
Nellie's Blog
[혼공자][챕터13-1] 컬렉션 프레임워크 본문
컬렉션 프레임워크란?
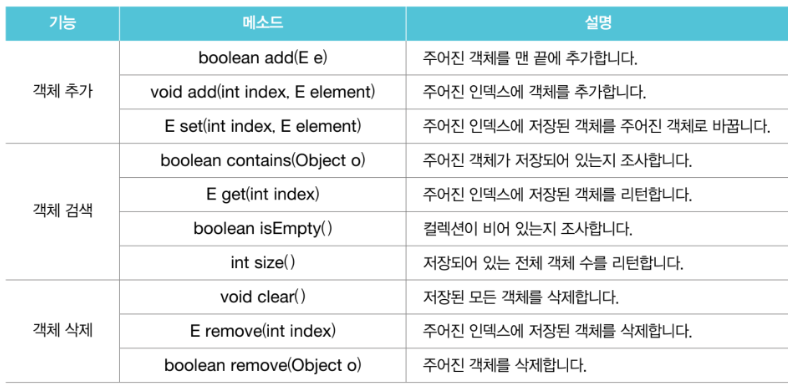
- 자료구조(Data Structure) 를 사용해서 객체들을 효율적으로 추가, 삭제, 검색할 수 있게 한 인터페이스와 구현클래스
- java.util 패키지에서 제공하는 프레임워크
- 배열은 선언 시 정한 크기(정한 용량)를 변경할 수 없고, 항목을 저장, 삭제, 추가하는 메소드가 없기 때문에 직접 인덱스를 사용해야 했던 불편함을 해결하기 위해 제공된 프레임워크
- 주요 인터페이스 : List, Set, Map

List 컬렉션
- 배열과 비슷하게 객체를 인덱스로 관리
- 배열과의 차이점 : 저장용량이 자동으로 증가, 객체를 저장할 때 자동 인덱스가 부여됨
- 객체 자체를 저장하는 것이 아닌 객체의 번지를 참조하며, 동일한 객체가 중복저장시 동일한 번지가 참조됨
- ArrayList, Vector, LinkedList

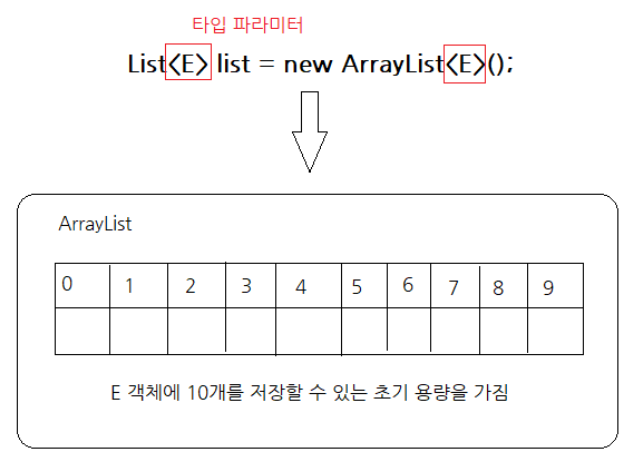
1. ArrayList
기본 생성자로 ArrayList 객체를 생성하면 내부에 10개의 객체를 저장할 수 있는 초기 용량(capacity)을 가지게 된다.
저장되는 객체 수가 늘어나면 용량이 자동으로 증가한다.
ArrayList는 List 인터페이스의 구현 클래스로 ArrayList에 객체를 추가하면 객체가 인덱스로 관리된다.
배열은 생성할 때 크기가 고정되고 사용 중에 크기를 변경할 수 없지만 ArrayList는 저장 용량(capacity)을 초과한 객체들이 들어오면 자동으로 저장 용량(capacity)이 늘어난다.
ArrayList에서 특정 인덱스의 객체를 제거하면 바로 뒤 인덱스부터 마지막 인덱스까지 모두 앞으로 1씩 당겨진다.
마찬가지로 특정 인덱스에 객체를 삽입하면 해당 인덱스부터 마지막 인덱스까지 모두 1씩 밀려난다.
따라서 빈번한 객체 삽입/삭제가 일어나는 곳에서는 ArrayList보다 LinkedList를 사용하는것이 좋다.

2. Vector

Vector는 ArrayList와 동일한 내부 구조
List<E> list = new Vector<E>();Vector는 스레드 동기화(synchronization)된 메소드로 구성된다.
복수의 스레드가 동시에 Vector에 접근해 객체를 추가, 삭제하더라도 스레드에 안전(thread safe)하다.
3. LinkedList
LinkedList는 List 구현 클래스. 인접 참조를 링크해서 체인처럼 관리한다.
특정 인덱스의 객체를 제거하면 앞뒤 링크만 변경, 삽입할 때도 앞뒤 링크만 변경 되어 빈번한 삽입/ 삭제에 용이하다.
List<E> list = new LinkedList<E>();
List<E> list = new LinkedList<>();




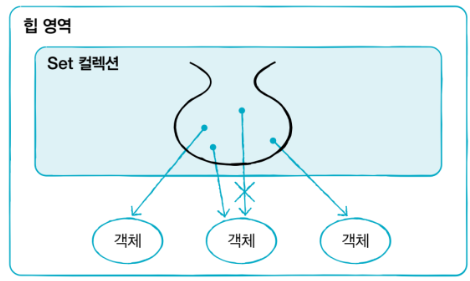
Set 컬렉션
- Set 컬렉션은 저장 순서가 유지 되지 않고, 객체를 중복해서 저장할 수 없다.
- null도 하나만 저장할 수 있다.
- HashSet, LinkedHashSet, TreeSet
- Set 컬렉션은 인덱스로 객체를 가져오는 메서드가 없다. 대신 반복자(Iterator)를 제공한다.

- 반복자 Iterator
Set 객체에 .iterator( )메소드를 호출하면, Iterator 인터페이스를 구현한 객체가 리턴된다.
Iterator 객체에 아래 메소드를 호출하여 전체 원소를 가져오게 할 수 있다.
또는 향상된 for문을 이용해도 전체 객체를 대상으로 반복할수 있다.
Set<String> set = ...;
Iterator<String> iterator = set.iterator();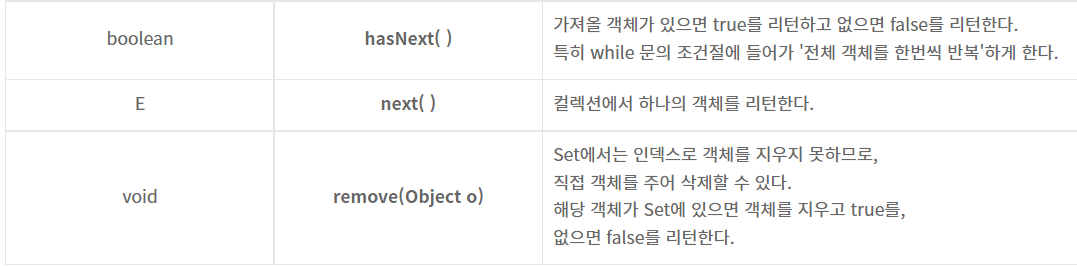
1. HashSet
HashSet은 Set 인터페이스 구현 클래스이다.
Set<E> set = new HashSet<E>();
// String 객체를 저장하는 HashSet 생성 방법
Set<String> set = new HashSet<String>();
Set<String> set = new HashSet<>();
HashSet이 판단하기에 동일한 객체로 판단하는 방법은,
저장할 객체에 hashCode( ) 메소드를 호출하여 기존 객체들의 hashCode와 동일한지 확인하고
equlas( )메소드로 두 객체를 비교하여 true이면 저장하지 않는다.
이 과정에서 hashCode( )와 equals( ) 메소드의 오버로딩이 필요하다.
만약 자바에서 제공하는 클래스를 사용하는 경우, 이미 오버로딩이 되어있겠지만
직접 만드는 클래스를 HashSet에 저장하는 경우 hashCode( )와 equals( ) 메소드의 오버로딩은 필수적이다.
hash 값을 사용하는 Collection(HashMap, HashSet, HashTable)은 객체가 논리적으로 같은지 비교할 때 아래 그림과 같은 과정을 거친다.

Map 컬렉션
- Map 컬렉션은 키(key)와 값(value)으로 구성된 Map.Entry 객체를 저장하는 구조를 가진다.
- 키는 중복 저장할 수 없지만 값은 중복 저장 될 수 있다.
- 기존에 저장된 키에 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대체된다.
- HashMap, Hashtable, LinkedHashMap, Properties, TreeMap 등


1. HashMap
HashMap은 Map 인터페이스를 구현한 대표적인 Map 컬렉션.
동일키 조건으로 hashCode()의 리턴값과 equals()가 true를 반환해야 한다.
Map<K, V> map = new HashMap<K, V>();
Map<String, Integer> map = new HashMap<String, Integer>();
Map<String, Integer> map = new HashMap<>();
2. Hashtable
Hashtable은 HashMap과 동일한 구조를 가진다.
차이점은 Hashtable은 동기화된(synchronized) 메서드로 구성되어 있어 멀티스레드가 동시에 Hashtable의 메서드를 실행할 수 없어 Hashtable은 스레드에 안전하다.
Map<K, V> map = new Hashtable<K, V>();
Map<String, Integer> map = new Hashtable<String, Integer>();
Map<String, Integer> map = new Hashtable<>();
혼자 공부하는 자바
https://wan-blog.tistory.com/34
https://ninetynine-2026.tistory.com/142
'Back-end > java' 카테고리의 다른 글
| Illegal invocation 에러 (415에러) (0) | 2023.09.12 |
|---|---|
| [리눅스]리눅스 서버에서 톰캣을 강제종료 하는 방법 (Web server failed to start. Port 8080 was already in use. 해결) (0) | 2023.06.27 |
| [혼공자][챕터10] 예외처리 (0) | 2022.12.07 |
| [혼공자][챕터5] 참조타입 (0) | 2022.11.11 |
| [혼공자][챕터4] 조건문과 반복문 (0) | 2022.11.10 |



