[timescaledb] 시계열 DB Memory 모니터링 (어디서 메모리를 잡아먹는지 분석하기..)
Kafka → Hadoop , timescaleDB, Redis, EMQX 스트리밍 부하 테스트를 하는데 유난히 timescaledb가 메모리를 많이 잡아먹었다..
초당 1만건 전송하여 확인한 기록이다.
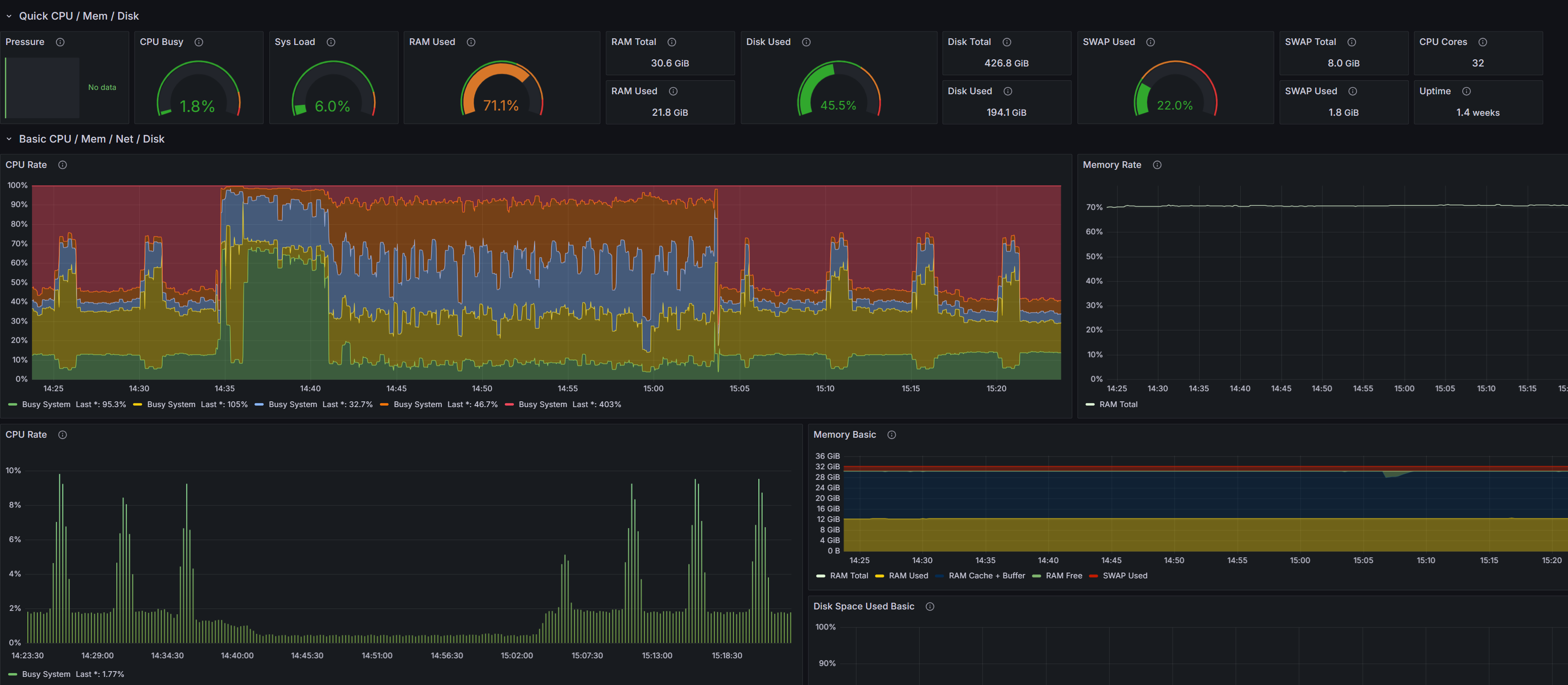
내가 직접 만든 Grafana로 계속 모니터링을 하는 중인데,
Spark와 timescaledb에서 Ram을 많이 잡아먹고, OOM에러도 종종 일어난다.
저 RAM 부분이 노란색이 되면 뭔가 예민해진다. 저러고 OOM 터져서 죽은적이 너무 많음 ㅜㅜ
리눅스 서버에서 docker stats로 메모리 사용량도 같이 확인을 해봄.
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a02167556cba node_exporter 0.00% 29.35MiB / 30.59GiB 0.09% 38.4MB / 1.1GB 148MB / 0B 38
4107b7119324 wowza 0.69% 1.82GiB / 30.59GiB 5.95% 803kB / 5.92MB 735MB / 1.93MB 1135
9e8c3d2b6438 redis-slave-3 6.19% 20.61MiB / 30.59GiB 0.07% 21.1GB / 20.1GB 6.93GB / 461GB 7
8d56f5793411 redis-master-3 0.00% 0B / 0B 0.00% 0B / 0B 0B / 0B 0
**35511d11ca3c timescaledb 25.76% 6.946GiB / 30.59GiB 22.71% 26.6GB / 1.46GB 2.22GB / 72.5GB 11**
3b06e5f352cb kafka2 2.71% 3.287GiB / 30.59GiB 10.74% 30GB / 121GB 14.8GB / 197GB 184
0e0d47ccd151 zookeeper2 0.19% 827.2MiB / 30.59GiB 2.64% 516MB / 763MB 568MB / 50.3MB 155
5db984913c9b datanode1 26.76% 3.957GiB / 30.59GiB 12.93% 579GB / 325GB 19.9GB / 85.2GB 597
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a02167556cba node_exporter 0.00% 29.35MiB / 30.59GiB 0.09% 38.4MB / 1.1GB 148MB / 0B 38
4107b7119324 wowza 0.78% 1.82GiB / 30.59GiB 5.95% 803kB / 5.92MB 735MB / 1.93MB 1135
9e8c3d2b6438 redis-slave-3 7.34% 20.74MiB / 30.59GiB 0.07% 21.1GB / 20.1GB 6.93GB / 461GB 7
8d56f5793411 redis-master-3 0.00% 0B / 0B 0.00% 0B / 0B 0B / 0B 0
**35511d11ca3c timescaledb 24.51% 6.949GiB / 30.59GiB 22.72% 26.6GB / 1.46GB 2.22GB / 72.5GB 11**
3b06e5f352cb kafka2 3.57% 3.287GiB / 30.59GiB 10.75% 30GB / 121GB 14.8GB / 197GB 184
0e0d47ccd151 zookeeper2 0.22% 827.2MiB / 30.59GiB 2.64% 516MB / 763MB 568MB / 50.3MB 155
5db984913c9b datanode1 254.77% 4.162GiB / 30.59GiB 13.61% 579GB / 325GB 19.9GB / 85.2GB 596
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a02167556cba node_exporter 0.00% 29.02MiB / 30.59GiB 0.09% 38.4MB / 1.1GB 148MB / 0B 38
4107b7119324 wowza 1.45% 1.82GiB / 30.59GiB 5.95% 803kB / 5.92MB 735MB / 1.93MB 1135
9e8c3d2b6438 redis-slave-3 6.94% 20.78MiB / 30.59GiB 0.07% 21.5GB / 20.5GB 6.93GB / 464GB 7
8d56f5793411 redis-master-3 0.00% 0B / 0B 0.00% 0B / 0B 0B / 0B 0
**35511d11ca3c timescaledb 25.46% 7.227GiB / 30.59GiB 23.63% 27.4GB / 1.48GB 2.22GB / 74.8GB 11**
3b06e5f352cb kafka2 2.93% 3.363GiB / 30.59GiB 11.00% 30.2GB / 121GB 14.8GB / 197GB 184
0e0d47ccd151 zookeeper2 0.20% 827.2MiB / 30.59GiB 2.64% 516MB / 763MB 568MB / 50.3MB 155
5db984913c9b datanode1 0.37% 3.931GiB / 30.59GiB 12.85% 579GB / 325GB 19.9GB / 85.2GB 543
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a02167556cba node_exporter 0.00% 31.12MiB / 30.59GiB 0.10% 38.7MB / 1.11GB 151MB / 0B 38
4107b7119324 wowza 1.52% 1.808GiB / 30.59GiB 5.91% 808kB / 5.95MB 736MB / 1.94MB 1135
9e8c3d2b6438 redis-slave-3 4.71% 20.65MiB / 30.59GiB 0.07% 27.1GB / 27GB 6.99GB / 490GB 7
**35511d11ca3c timescaledb 24.73% 8.224GiB / 30.59GiB 26.89% 53.1GB / 2.32GB 2.99GB / 128GB 11**
3b06e5f352cb kafka2 2.79% 3.396GiB / 30.59GiB 11.10% 36.4GB / 129GB 17.1GB / 199GB 184
0e0d47ccd151 zookeeper2 0.21% 795.9MiB / 30.59GiB 2.54% 524MB / 770MB 568MB / 50.3MB 155
5db984913c9b datanode1 0.96% 8.905GiB / 30.59GiB 29.11% 614GB / 349GB 22GB / 90.3GB 775
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a02167556cba node_exporter 0.00% 28.73MiB / 30.59GiB 0.09% 38.8MB / 1.12GB 156MB / 0B 38
4107b7119324 wowza 1.06% 1.784GiB / 30.59GiB 5.83% 808kB / 5.95MB 736MB / 1.94MB 1135
9e8c3d2b6438 redis-slave-3 6.52% 19.71MiB / 30.59GiB 0.06% 35.3GB / 34.2GB 7.01GB / 524GB 7
8d56f5793411 redis-master-3 0.00% 0B / 0B 0.00% 0B / 0B 0B / 0B 0
**35511d11ca3c timescaledb 24.32% 8.174GiB / 30.59GiB 26.72% 67.1GB / 2.78GB 4.04GB / 150GB 11**
3b06e5f352cb kafka2 5.25% 4.813GiB / 30.59GiB 15.73% 40.4GB / 139GB 17.7GB / 199GB 184
0e0d47ccd151 zookeeper2 0.25% 729.2MiB / 30.59GiB 2.33% 526MB / 772MB 571MB / 50.3MB 155
5db984913c9b datanode1 255.36% 7.367GiB / 30.59GiB 24.08% 621GB / 351GB 22.2GB / 91.2GB 780
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a02167556cba node_exporter 2.48% 28.55MiB / 30.59GiB 0.09% 38.9MB / 1.12GB 156MB / 0B 38
4107b7119324 wowza 0.82% 1.766GiB / 30.59GiB 5.77% 811kB / 5.96MB 736MB / 1.95MB 1135
9e8c3d2b6438 redis-slave-3 5.40% 18.86MiB / 30.59GiB 0.06% 42.8GB / 40.7GB 7.02GB / 555GB 7
8d56f5793411 redis-master-3 0.00% 0B / 0B 0.00% 0B / 0B 0B / 0B 0
**35511d11ca3c timescaledb 26.67% 8.148GiB / 30.59GiB 26.64% 80GB / 3.2GB 4.85GB / 173GB 11**
3b06e5f352cb kafka2 3.52% 5.395GiB / 30.59GiB 17.64% 44GB / 149GB 18GB / 200GB 184
0e0d47ccd151 zookeeper2 0.07% 654.9MiB / 30.59GiB 2.09% 528MB / 773MB 589MB / 50.3MB 155
5db984913c9b datanode1 0.47% 6.959GiB / 30.59GiB 22.75% 628GB / 352GB 22.2GB / 91.9GB 772
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a02167556cba node_exporter 0.00% 29.14MiB / 30.59GiB 0.09% 38.9MB / 1.12GB 160MB / 0B 38
4107b7119324 wowza 1.41% 1.765GiB / 30.59GiB 5.77% 811kB / 5.96MB 736MB / 1.95MB 1135
9e8c3d2b6438 redis-slave-3 0.37% 18.62MiB / 30.59GiB 0.06% 44.2GB / 42GB 7.02GB / 561GB 7
**35511d11ca3c timescaledb 24.86% 8.141GiB / 30.59GiB 26.61% 83GB / 3.3GB 5.18GB / 179GB 11**
3b06e5f352cb kafka2 2.73% 5.608GiB / 30.59GiB 18.33% 44.7GB / 151GB 18.1GB / 200GB 184
0e0d47ccd151 zookeeper2 0.10% 650.2MiB / 30.59GiB 2.08% 528MB / 774MB 595MB / 50.3MB 155
5db984913c9b datanode1 285.56% 6.961GiB / 30.59GiB 22.76% 629GB / 353GB 22.2GB / 92.3GB 779
멀쩡해 보이는데 timescaledb가 점점 메모리 사용량이 높아지며 신경쓰이게 했다.
어떤 놈이 메모리를 먹고있는건지 분석해봤다....
timescaledb 컨테이너 접속 및 db명 조회
[platform@CES ~]$ docker exec -it timescaledb bash
postgres=# \\l
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | ICU Locale | ICU Rules | Access privileges
-----------+----------+----------+-----------------+---------+---------+------------+-----------+-----------------------
postgres | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | |
template0 | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
(3 rows)
이건 별거 없고,,,
postgres db 접속 및 현재 진행 중인 쿼리 확인
postgres=# psql -U postgres -d postgres
postgres=# SELECT pid, state, query
FROM pg_stat_activity
WHERE state != 'idle';
pid | state | query
-------+--------+--------------------------
90418 | active | SELECT pid, state, query+
| | FROM pg_stat_activity +
| | WHERE state != 'idle';
(1 row)
확인해보니 방금 작성한 쿼리말고는 실행되는 쿼리는 없다.
Autovacuum 및 Dead Tuple(삭제되었지만 정리되지 않은 데이터)을 확인
postgres=# SELECT relname, last_autovacuum, n_dead_tup
FROM pg_stat_user_tables
WHERE n_dead_tup > 0;
relname | last_autovacuum | n_dead_tup
---------------------------------+-------------------------------+------------
_hyper_24_1447_chunk | 2024-12-24 09:10:45.824003+00 | 17
chunk_constraint | | 4
dimension_slice | | 55
bgw_job_stat | | 4
tb_realtime_vehicle_data_250103 | 2025-01-03 03:20:18.333171+00 | 31878
chunk_index | | 4
chunk | | 2
_hyper_24_1376_chunk | 2024-12-24 09:06:15.627968+00 | 1263
(8 rows)
뭔가 꺼림칙한 놈이 나옴.
죽은 튜플들을 정리를 안하고 있나? 싶어서 분석해 봄
-
- Dead Tuple 개수가 상대적으로 많음:
- _hyper_24_1376_chunk: 1,263개
- _hyper_24_1447_chunk: 17개
- Hypertable에서 생성된 Chunk 테이블로, TimescaleDB의 시계열 데이터를 저장
- Autovacuum이 작동했지만 완전히 정리되지 않았을 가능성이 있음해당 결과는 pg_stat_user_tables에서 Autovacuum 및 Dead Tuple(삭제되었지만 정리되지 않은 데이터)을 확인한 것이다.
1. 주요 내용- relname: 테이블 이름
- last_autovacuum: 해당 테이블에서 Autovacuum이 마지막으로 실행된 시간
- n_dead_tup: 테이블 내에서 삭제되었지만 VACUUM이 수행되지 않아 여전히 존재하는 레코드(Dead Tuple) 수
2. 확인 사항- Dead Tuple 개수: 31,878개
- 마지막 Autovacuum 실행 시간: 2025-01-03 03:20:18
- 이 테이블은 최근 Autovacuum이 실행되었지만 여전히 Dead Tuple이 많다.
3. 문제 원인- Dead Tuple이 많은 이유:
- 빈번한 데이터 변경 작업: 대량의 INSERT, UPDATE, DELETE 작업이 Dead Tuple을 생성.
- Autovacuum 설정 미흡: 기본 Autovacuum 설정으로 인해 정리가 지연될 수 있음.
- TimescaleDB Hypertable 특성: Chunk 테이블에 데이터가 분산되며, VACUUM이 자주 실행되지 않을 가능성.
4. 해결 방법 - Dead Tuple 개수가 상대적으로 많음:
- Dead Tuple이 많은 테이블에 대해 VACUUM을 수동으로 실행하여 정리하자.
Dead Tuple 비율 확인 (5% 미만이 정상, 5~20% 이면 관찰 필요, 20% 이상이면 비정상)
postgres=# SELECT relname,
n_dead_tup,
n_live_tup,
ROUND(n_dead_tup::NUMERIC / (n_live_tup + n_dead_tup) * 100, 2) AS dead_tuple_ratio
FROM pg_stat_user_tables
WHERE n_dead_tup > 0;
relname | n_dead_tup | n_live_tup | dead_tuple_ratio
----------------------+------------+------------+------------------
_hyper_24_1447_chunk | 17 | 7198 | 0.24
chunk_constraint | 4 | 764 | 0.52
dimension_slice | 55 | 382 | 12.59
bgw_job_stat | 4 | 0 | 100.00
chunk_index | 4 | 1145 | 0.35
chunk | 2 | 382 | 0.52
_hyper_24_1376_chunk | 1263 | 7196 | 14.93
(7 rows)
그렇게 심하게 잡아먹고 있진 않았다..
autovacuum 상태 확인
vi /home/postgres/pgdata/data/postgresql.conf
#------------------------------------------------------------------------------
# AUTOVACUUM
#------------------------------------------------------------------------------
#autovacuum = on # Enable autovacuum subprocess? 'on'
# requires track_counts to also be on.
autovacuum_max_workers = 10 # max number of autovacuum subprocesses
# (change requires restart)
autovacuum_naptime = 10 # time between autovacuum runs
**#autovacuum_vacuum_threshold = 50 # min number of row updates before # 🎯 현재 Dead Tuple 개수가 50개 이상이면 실행**
# vacuum
#autovacuum_vacuum_insert_threshold = 1000 # min number of row inserts
# before vacuum; -1 disables insert
# vacuums
#autovacuum_analyze_threshold = 50 # min number of row updates before
**#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum #🎯 테이블의 20% 이상의 Dead Tuple이 있으면 실행**
#------------------------------------------------------------------------------
# RESOURCE USAGE (except WAL)
#------------------------------------------------------------------------------
# - Memory -
shared_buffers = 7831MB # min 128kB # **🎯** 전체 메모리의 25%~40% 권장
# (change requires restart)
#huge_pages = try # on, off, or try
# (change requires restart)
#huge_page_size = 0 # zero for system default
# (change requires restart)
#temp_buffers = 8MB # min 800kB
#max_prepared_transactions = 0 # zero disables the feature
# (change requires restart)
# Caution: it is not advisable to set max_prepared_transactions nonzero unless
# you actively intend to use prepared transactions.
work_mem = 2505kB # min 64kB # **🎯** 대량 작업 시 증가 가능
#hash_mem_multiplier = 2.0 # 1-1000.0 multiplier on hash table work_mem
maintenance_work_mem = 2047MB # min 1MB
#autovacuum_work_mem = -1 # min 1MB, or -1 to use maintenance_work_mem
#logical_decoding_work_mem = 64MB # min 64kB
얘도 디폴트 값이었다.
압축 정책 확인
postgres=# SELECT * FROM timescaledb_information.compression_settings;
hypertable_schema | hypertable_name | attname | segmentby_column_index | orderby_column_index | orderby_asc | orderby_nullsfirst
-------------------+-----------------+---------+------------------------+----------------------+-------------+--------------------
(0 rows)
postgres=#
현재 압축 정책이 없다. 압축 정책을 추가해줘야겠음 !!!!
- 압축 정책 추가하면 메모리와 디스크 사용량 감소 가능!
SELECT add_compression_policy('your_hypertable_name', INTERVAL '30 days');- 이 설정은 30일 이전의 데이터를 자동으로 압축해준다고 한다!
데이터베이스 백그라운드 라이터의 버퍼 관리 통계 확인
postgres=# SELECT
buffers_checkpoint AS "Written by Checkpoints",
buffers_clean AS "Clean Buffers",
buffers_backend AS "Written by Backends"
FROM pg_stat_bgwriter;
Written by Checkpoints | Clean Buffers | Written by Backends
------------------------+---------------+---------------------
5415457 | 2693 | 3002002
(1 row)
- 높은 Written by Checkpoints 값
- 체크포인트 과정에서 메모리를 디스크로 내보낸 데이터가 많다는 것을 의미한다. 이는 트랜잭션 처리량이 높거나, shared_buffers가 충분히 활용되고 있음을 나타냄
- 낮은 Clean Buffers 값
- 클린 버퍼 작업이 상대적으로 적게 수행되었음을 나타냄. 이는 시스템이 클린 버퍼 정리에 대해 효율적으로 동작 중
- Written by Backends 값
- 클라이언트(백엔드)가 직접 디스크에 기록하는 데이터가 많음. 이는 버퍼가 꽉 차거나 충분히 캐시되지 않아 디스크 I/O가 빈번히 발생할 수 있음을 나타낸다고 한다.
이것도 뭐 문제 없군 ,,,,,,
버퍼 사용 현황 확인
postgres=# SELECT
sum(blks_read) AS "Blocks Read",
sum(blks_hit) AS "Blocks Hit",
sum(blks_hit) * 100.0 / (sum(blks_hit) + sum(blks_read)) AS "Cache Hit Ratio (%)"
FROM pg_stat_database;
Blocks Read | Blocks Hit | Cache Hit Ratio (%)
-------------+------------+---------------------
165898 | 413661536 | 99.9599113093116006
(1 row)
- 캐시 히트율이 매우 높음 (99.96%)
- 대부분의 데이터 요청이 디스크가 아닌 메모리(shared_buffers)에서 처리되며 shared_buffers 설정이 적절하고, PostgreSQL이 메모리 캐시를 효율적으로 활용하고 있음을 나타냄
- Blocks Read 값이 낮음
- 디스크 I/O 작업이 비교적 적게 발생
- 메모리 캐시에 의해 대부분의 데이터 요청이 처리되고 있어 디스크 의존도가 낮은 이상적인 상태를 나타냄
- Blocks Hit 값이 높음
- 메모리 캐시에서 읽은 데이터 블록이 많아, 성능이 최적화된 상태임을 보여줌
- 애플리케이션 성능에 영향을 미치는 디스크 I/O 병목이 거의 없다.
체크포인트 설정 확인 (디스크에 쓰는 작업)
postgres=# SHOW checkpoint_timeout;
checkpoint_timeout
--------------------
5min
(1 row)
postgres=# SHOW max_wal_size;
max_wal_size
--------------
1GB
(1 row)
- checkpoint_timeout = 5min
- PostgreSQL은 5분마다 체크포인트를 실행하도록 설정되어 있으며
- 기본값(5분)인데, 데이터 변경 작업이 많은 워크로드에서는 체크포인트가 너무 자주 발생하여 디스크 I/O 부하를 증가시킬 수 있다. 적절히 조절하기.
- max_wal_size = 1GB
- 최대 WAL(Write Ahead Log) 크기가 1GB로 설정되어 있다.
- WAL이 1GB에 도달하면 강제로 체크포인트가 실행된다. 적절히 조절하자.
큰 문제는 없어 보였으며 , 압축 정책만 조절하고 다시 반영해봐야겠다.
스파크 OOM에러 , JVM OOM 에러 , 스택에러 등 메모리 문제가 자주 발생하니 메모리 문제에 예민해지는 듯 ㅠㅠ
교훈 : 메모리 공부를 더 열심히 하자.